在 上一篇post 中,我介绍了机器学习中树模型在时间序列中的运用方式,举例了如何构建特征变量并XGBoost进行时序预测,但并不是所有的时序预测都可以使用树模型进行建模。
在这篇post中,我将带来一些对树模型在时序方面的运用条件的思考,该想法源于之前我在做时序预测时出现的收敛问题。
1. 需要至少一个以上的特征变量,并且尽量保证特征变量足够多。可以从时序变量 Y 以外寻找相关的影响因素作为特征变量,也可以从 Y 中提取特征变量
树模型的基本运作原理是通过对变量不断进行分裂,每个特征分割点作为枝节点,所有的叶子即为最终树模型要输出的各种结果。如果没有特征变量或者特征变量过少,将导致无输出结果或者叶子太少,误差过大。
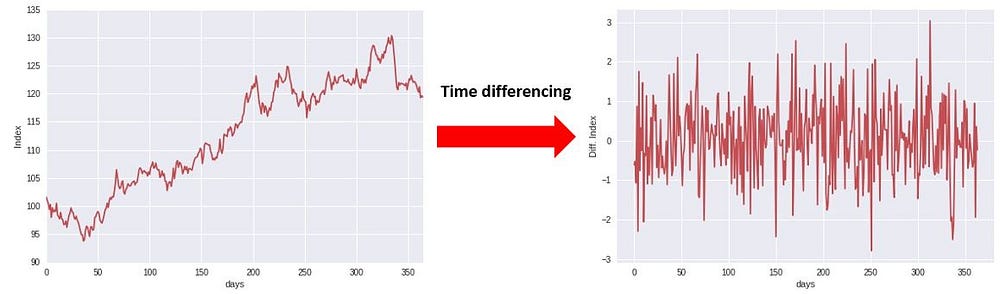
2. 直接对时序变量预测时,要求时序变量基本平稳,无趋势
在上一篇post中的例子可以看到,xgboost的拟合预测效果不错,但是可以发现使用到的数据是基本平稳,无趋势的。

为什么需要被预测的时序变量是平稳的呢
对这个问题的思考在某次模拟时,我利用训练样本训练xgboost预测输出变量在某个区间的最大值发现的,我尝试不断的修改参数,利用启发式算法找区间内的模型最优输出解,但是结果都是:得到的最优解没法超过训练样本中的最大值,这说明模型输出来的最优解结果误差很大,于是我重新回忆树模型的构建原理,思考良久后,最终找到了原因:树模型没有办法进行“外推”。具体解释如下:
树模型是通过启发式算法与目标函数、损失函数相结合,从而对训练数据求解出最佳分割点与最佳分割数,然后对该节点进行叶子分割,不断重复最后构建出树模型和模型中的 M 片有限的叶子(即 M 个结果),这也决定了不论输入模型的新特征值为多少,最后都将输出为 M 个结果中的一个,尤其当面对求最优解、预测趋势变量时,树模型通过查看数据点属于哪个“叶子”并将训练集中目标变量的平均值分配给该点来进行回归预测,即一旦模型训练结束,不管输入什么变量,结果:前者收敛,介于训练数据的最大和最小值之间;后者:结果也将位于 M 个数值中间,无法“推断”到模型尚未看到的数据,这也是为什么树形模型在时间序列预测时要求序列结果不存在趋势,否则泛化性很低、误差极大。
举个例子:
当使用树模型拟合预测下列图中的第二个时序数据时,树模型的拟合效果将会很好,但是一旦使用其预测红线以外的部分数据时,模型得到结果将可能时其他三幅图,此时按我们的直觉判断,红线之外,变量整体上大概率会继续呈上升趋势,因此模型预测的结果将的大概率与实际情况有较大的误差。

但是这是不是表明不能使用树模型对时序变量进行预测呢?
答案是肯定是否定的。
查阅了一些资料后,发现可以换一种思路找到解决方式:
- 重新构建预测的目标时序变量。例如,你可以先使用简单的线性模型与时间变量 Y 拟合,使用真实值与预测值之间的残差作为目标输出,从而训练树模型,即预测线性模型与时间变量之间的误差,此时得到最终预测结果为:树模型预测的误差+线性模型的预测值,同时也可以使用变化率作为特征等等。
- 对趋势的时间序列进行差分。使之转化为平稳的时间序列,以此再构建树模型对差分后的平稳序列进行预测;如下图: