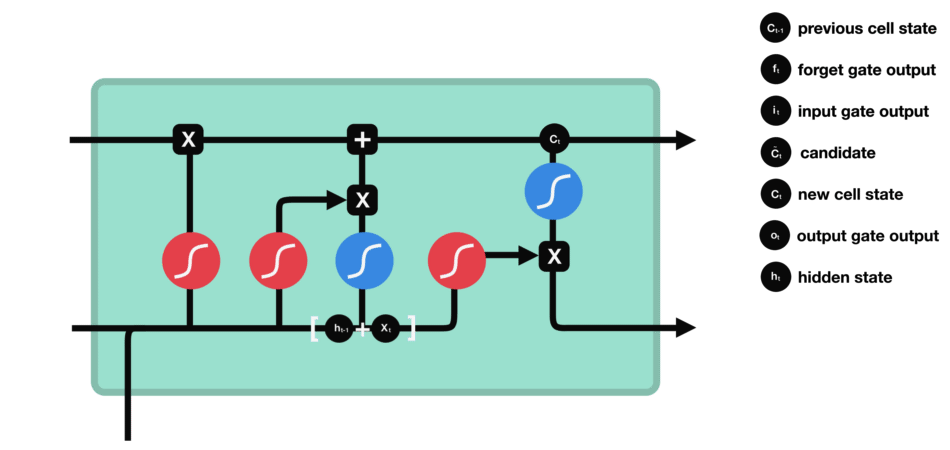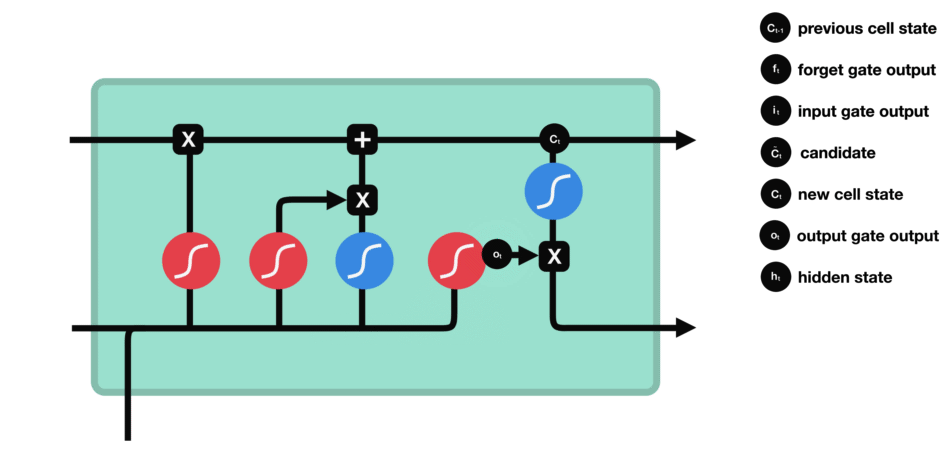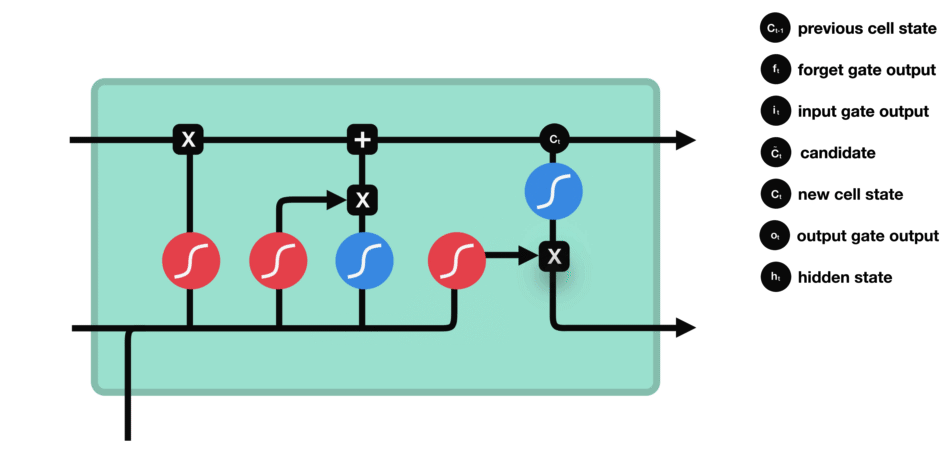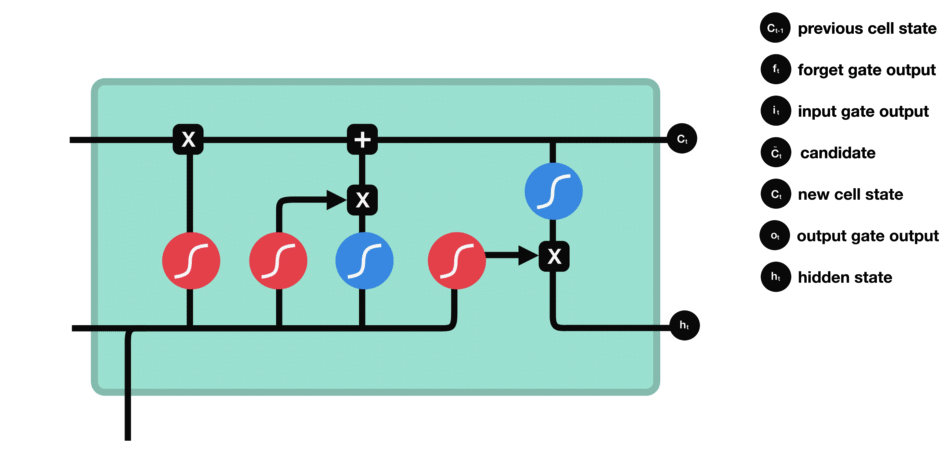
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| def data_lstm(df):
# 1. 时序数据的标准化处理及训练集和验证集划分
scale = MinMaxScaler(feature_range = (0, 1))
df = scale.fit_transform(df)
train_size = int(len(df) * 0.80)
test_size = len(df) - train_size
# 2. 由于时序变量具有先后关系,因此划分数据集时一般先前作为训练集、后者作为验证集
train, test = df[0:train_size, :], df[train_size:len(df), :]
return(train_size, test_size, train, test, df, scale)
# 2. lookback 表示以过去的几个日期作为主要预测变量,这里我选择的默认为1
# 输入数据集 和 输出数据集 的的建立
def create_data_set(dataset, look_back=1):
data_x, data_y = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
data_x.append(a)
data_y.append(dataset[i + look_back, 0])
return np.array(data_x), np.array(data_y)
# 3. 训练集和验证集的数据转化
def lstm(train, test, look_back=1):
X_train,Y_train,X_test,Y_test = [],[],[],[]
X_train,Y_train = create_data_set(train, look_back)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test, Y_test = create_data_set(test, look_back)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
return (X_train, Y_train, X_test, Y_test)
# 4. 定义LSTM模型结构, 内部的结构参数可以根模型的拟合结果进行修改
def lstm_model(X_train, Y_train, X_test, Y_test):
# 第一层,256个神经元,以及0.3的概率dropout进行正则
regressor = Sequential()
regressor.add(LSTM(units = 256, return_sequences = True, input_shape = (X_train.shape[1], 1)))
regressor.add(Dropout(0.3))
# 第二层,128个神经元,以及0.3的概率dropout进行正则
regressor.add(LSTM(units = 128, return_sequences = True))
regressor.add(Dropout(0.3))
# 第三层,128个神经元,以及0.3的概率dropout进行正则
regressor.add(LSTM(units = 128))
regressor.add(Dropout(0.3))
regressor.add(Dense(units = 1))
regressor.compile(optimizer = 'adam', loss = 'mean_squared_error') # 损失函数为均方误差
reduce_lr = ReduceLROnPlateau(monitor='val_loss', patience=5)
# 下面的参数都可以进行修改,一般而言batchsize越大会越好些,epochs表示迭代次数,大家根据结果,大概何时收敛即可定为多少
history =regressor.fit(X_train, Y_train, epochs = 80, batch_size = 8,validation_data=(X_test, Y_test), callbacks=[reduce_lr],shuffle=False)
return(regressor, history)
# 5. 模型训练
def loss_epoch(regressor, X_train, Y_train, X_test, Y_test, scale, history):
train_predict = regressor.predict(X_train)
test_predict = regressor.predict(X_test)
# 将预测值进行反标准化,即还原
train_predict = scale.inverse_transform(train_predict)
Y_train = scale.inverse_transform([Y_train])
test_predict = scale.inverse_transform(test_predict)
Y_test = scale.inverse_transform([Y_test])
# 输出训练集和验证集的绝对误差和均方误差
print('Train Mean Absolute Error:', mean_absolute_error(Y_train[0], train_predict[:,0]))
print('Train Mean Squared Error:',np.sqrt(mean_squared_error(Y_train[0], train_predict[:,0])))
print('Test Mean Absolute Error:', mean_absolute_error(Y_test[0], test_predict[:,0]))
print('Test Root Mean Squared Error:',np.sqrt(mean_squared_error(Y_test[0], test_predict[:,0])))
# 损失值结果 可视化
plt.figure(figsize=(16,8))
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Test Loss')
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(loc='upper right')
plt.show()
return(train_predict, test_predict, Y_train, Y_test)
# 6. 绘制拟合图,对未来进行预测
def Y_pre(Y_train, Y_test, train_predict, test_predict):
Y_real = np.vstack((Y_train.reshape(-1,1), Y_test.reshape(-1,1)))
Y_pred = np.vstack((train_predict[:,0].reshape(-1,1), test_predict[:,0].reshape(-1,1)))
return(Y_real, Y_pred)
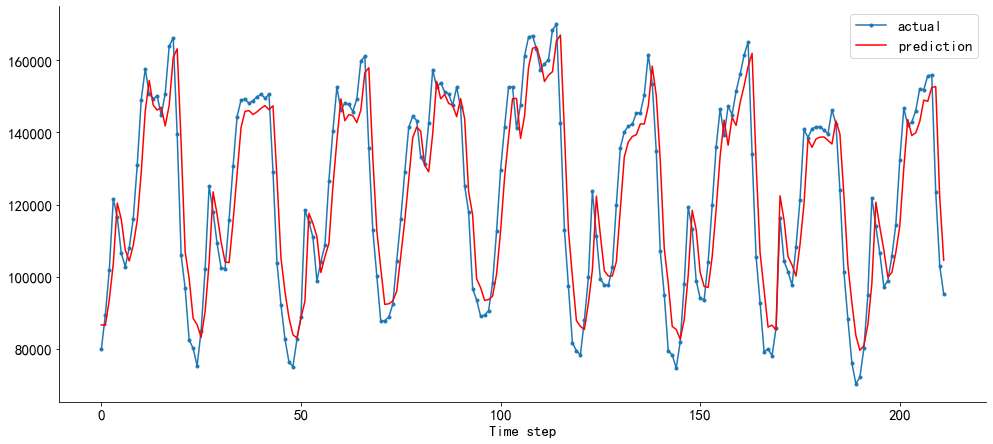
def plot_compare(n, Y_real, Y_pred):
aa=[x for x in range(n)]
plt.figure(figsize=(14,6))
plt.plot(aa, Y_real, marker='.', label="actual")
plt.plot(aa, Y_pred, 'r', label="prediction")
plt.tight_layout()
sns.despine(top=True)
plt.subplots_adjust(left=0.07)
plt.xticks(size= 15)
plt.yticks(size= 15)
plt.xlabel('Time step', size=15)
plt.legend(fontsize=15)
plt.show()
# 7. 根据一个真实的值预测连续的长度
def predict_sequences_multiple(model, firstValue, length, look_back=1):
prediction_seqs = []
curr_frame = firstValue
for i in range(length):
predicted = []
predicted.append(model.predict(curr_frame[-look_back:])[0,0])
curr_frame = np.insert(curr_frame, i+look_back, predicted[-1], axis=0)
prediction_seqs.append(predicted[-1])
return prediction_seqs
|